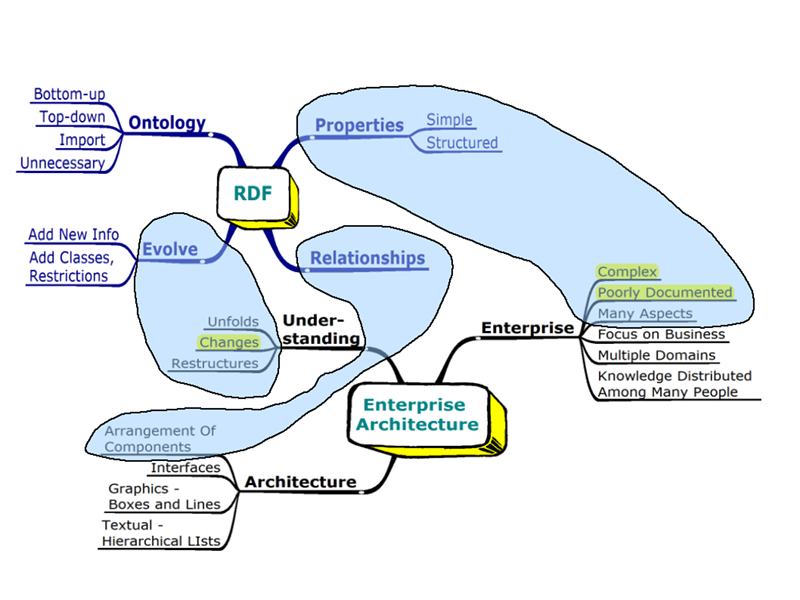
- Make RDF much easier
For "ordinary" people and programmers
- Enterprise and systems modeling
Simplify instance data collection and organization
- Hope for simplicity, flexibility, better interoperability, etc.


Plus ... not interoperable
Plus ... local identifiers, no semantics, ...
EA programs - e.g., Metis, Rose
Expensive
Steep learning curve
Hard to share data (XMI isn't that great)
Hard to get data out in new forms
Can be hard to restructure
Emphasis here is on early modeling, data collection. See wish list on next slide.
1. Easy collection of instance data
2. Data looks human- e.g., indented lists
3. Instance data can be machine-processed
4. Easy restructuring
5. Ability to include undefined or undescribed entities in the dataset
i.e., can be added even when their characteristics are not known
6. Ability to reclassify entities, even after instance data has been entered
7. Ability to extract the vocabulary (ontology)
8. Ability to create data entry templates
(to guide data collection)
(more coming on next slide)
9. Easy to add new properties
discovered as the model evolves
or during data collection activities
10. Take data collected using the (paper) templates and get it into the data set
11. Feasible to transform the dataset into other forms
For display, import into established tools, etc.
Fruit apples bananas milk eggs Paper products paper towels napkins
How a human would like it -
Organization org-id:OFS name:Office for Federated Systems member of:Federated Umbrella Organization
A small RDF subset looks similar -
<Organization
rdf:about='OFS'>
<rdfs:label>Office for Federated Systems</rdfs:label>
<member-of
rdf:resource='Federated-Umbrella-Organization'/>
</Organization>
It's already close, but we can do better
A simple structured text format really does the job -
Organization::
rdf:about::OFS
rdfs:label::Office for Federated Systems
member-of::
rdf:resource::Federated-Umbrella-Organization
Compare with the original -
Organization org-id:OFS name:Office for Federated Systems member of:Federated Umbrella Organization
A simple Python parser converts this into the RDF-XML form.
Rules for the structured text are in the full paper.
Convenient, but can also just use the RDF-XML form, not much harder.
Key points -
"Striped" structure - alternate resource and property
Use blank nodes (bnodes) for structured properties
(rdf:parseType='Resource')
Use XML shortcuts - entities, xml:base, namespaces - for readability
Modularize using external entities
Pull parts together using DTD, skeleton RDF file.
All together, these give readable, textual data format
Any resource can come in any order.
Top level (XML) element names represent the kinds of things (classes)
Restructure by moving properties under newly inserted bnode
Extract data for presentation using XSLT.
Annotations and labels can be added later
RDF processors Just Do The Right Thing.
Can use existing OWL ontology or derive one from the data
Everything needs an identifier but not everything needs a name at first.
Can use RDFS or OWL to give labels to kinds of resources and properties
owl:Class::
rdf:about::ObservingSystem
rdf:label::Observing System
@rdfs:subClassOf::
rdf:resource::System
; Note that we need to use the "@" character, because
; rdfs:subClassOf is not one of the three special
; attributes that are predefined in the translator.
RDF-XML for this fragment -
<owl:Class rdf:about='ObservingSystem'>
<rdfs:label>Observing System</rdfs:label>
<rdfs:subClassOf rdf:resource='System'></rdfs:subClassOf>
</owl:Class>
; Here is a bit of instance data
Org::
rdf:about::ofs
rdfs:label::Office for Federated Systems
acronym::OFS
homepage::http://www.example.com/ofs
member-of::
rdf:resource::fed-umbr-org
related-org::
rdf:parseType::Resource
role::
rdf:resource::fundedby
org::
rdf:resource::lga
Org::
rdf:about::fed-umbr-org
rdfs:label::Federated Umbrella Organization
acronym::FUO
Typical kinds of evolution - MUST be able to handle
Renaming
Name defined by defined by rdfs:label
Define and change in just one place
Adding And Splitting Structure
Most common need - see example on next slide
Reclassifying
Reparented, or to be declared to be a subclass of a new class
Done in one place, by direct manual typing or by a search-and-replace operation
Accidental Duplication
Using same identifier - no harm done, RDF processor will Do The Right Thing
Using different identifier -
Can fix in text editor using global search-and-replace for identifer, or
Use OWL owl:sameAs property. Processor must understand this property.
Original funding description
funding-profile::
funding-fy-profile::
date-fy::2006
budget-amount:500k
Oh, wait, we need to capture funding agency
funding-profile::
funding-fy-profile::
date-fy::2006
budget-amount::500k
funding-org::
rdf:resource::big-govt-agency
We're not done, see next slide
Oops, the client wants the funds shown in specific categories
funding-profile::
funding-fy-profile
date-fy::2006
budget-amount::
operational:400k
new-acquisition::100k
funding-org::
rdf:resource::big-govt-agency
This process will probably continue as we collect more data and learn more.
The RDF-subset/Structured Text approach works beautifully for these kinds of changes.
Typical DTD is clean and lean
<?xml version='1.0' encoding='utf-8'?> <!--================ URI shortcuts =================--> <!ENTITY model-orgs "http://tpassin.net/architecture/2007-04-10/orgs/"> <!ENTITY model-systems "http://tpassin.net/architecture/2007-04-10/systems/"> <!ENTITY model-person "http://tpassin.net/architecture/2007-04-10/person/"> <!--============= Entity for the base namespace ======--> <!ENTITY arch-ns "http://tpassin.net/architecture/2007-04-10/"> <!--=========== External entities containing the data ===============--> <!ENTITY base-ontology SYSTEM 'basemodel_ontology.ent'> <!ENTITY systems SYSTEM 'systems.ent'> <!ENTITY persons SYSTEM 'persons.ent'> <!ENTITY orgs SYSTEM 'orgs.ent'>
Again, clean and simple
<?xml version='1.0'?> <!DOCTYPE rdf:RDF SYSTEM "arch_rdf.dtd"> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns='&arch-ns;' xml:base='&arch-ns;' > &base-ontology; &systems; &persons; &orgs; </rdf:RDF>
1. Decide on base URI, key entities (can extend later)
2. Write DTD fragment to declare them
3. Write top-level RDF file to import DTD, define namespaces
4. Write text-format files with instance data (class definitions optional)
e.g., person.txt
5. Transform structured text files to RDF-XML
e.g., person.ent
6. Add one external entity declaration to DTD for each module (RDF-XML file)
7. Add a reference to each external entity in the body of the top-level RDF-XML file.
8. (optional) Can create all-in-one RDF-XML file by running through a good XML parser, like RXP.
Step 4 is most of the work - can be done by people with minimal training.
Many purposes -
Show structure
Show classes and properties
Show all instance data
Create templates for data collection
Transform to XMI or other format used by graphical tools
How? XSLT transforms work well
Possible because of simple, regular structure
- Stick with this format
- Pro: easy
- Con: Not many tools to work with the data as is
- Con: lots of identifiers to remember and navigate
- Import into RDF Database
- Pro: simple way to handle lots of data
- Con: few modeling tools that can use RDF data
- Convert to RDBMS
- Pro: easy, because RDF model is well-normalized already
- Con: proprietary, one-off data model
- Convert to modeling tool format (Metis, Rose, UML, etc)
- Pro: these tools have many capabilities
- Pro: Metis data format is nearly RDF already
- Pro: some clients mandate specific tool
- Con: may be difficult to transform data for tool.
- Com: expense and learning curve of tools.
Can have lots of identifiers to remember
Not unique to this approach, but no tool help for navigating and creating graphics.
Could write something ...
Good mnemonic naming conventions help a lot
How to incorporate non-text data
E.g., images, tables
Should be as simple as the basic structured text
Export to other tools
Need to roll your own